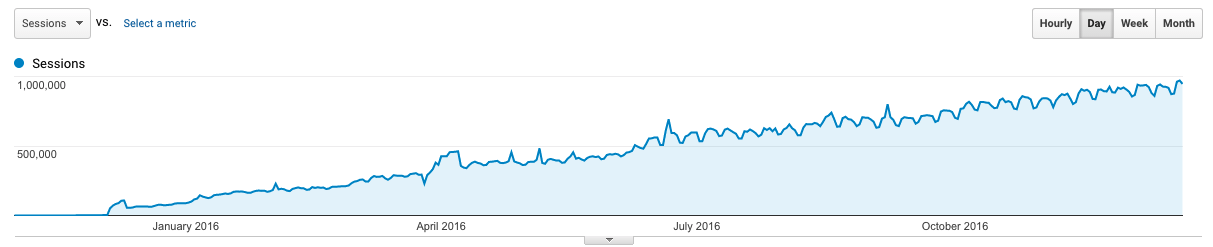
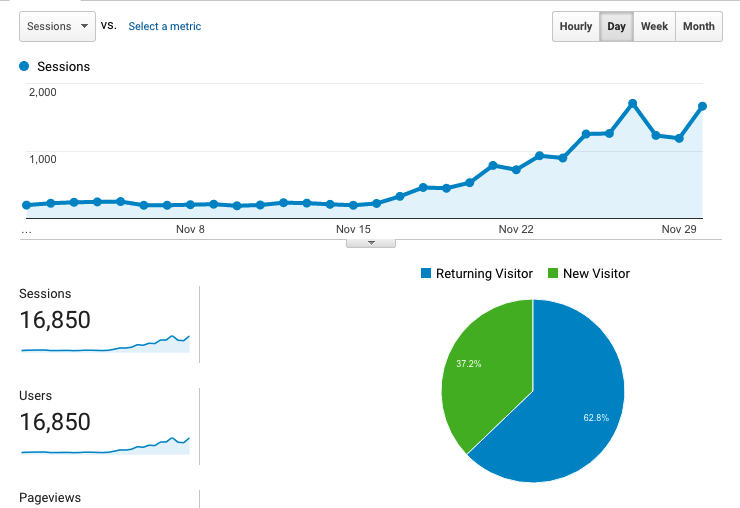
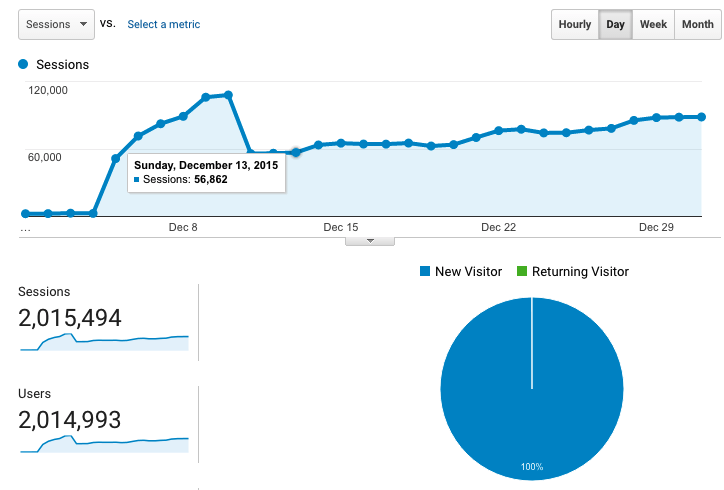
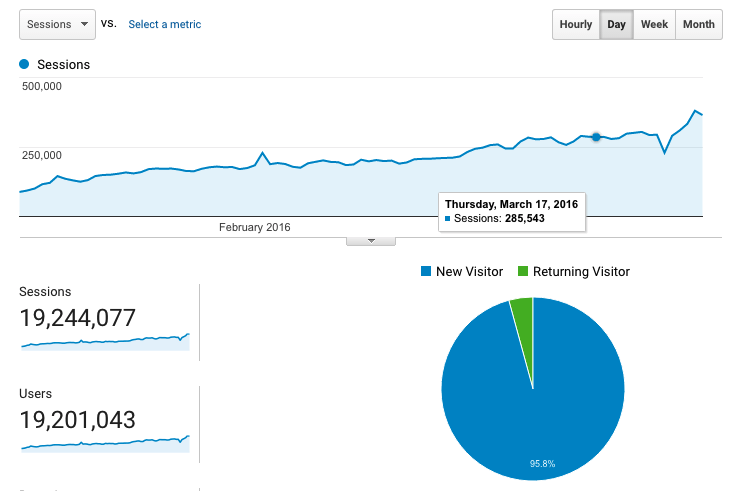
For the past decade I was a software engineer at a number of different companies. At each company I learned a lot of stuff, honed my craft, and eventually decided that I wanted to be a manager. I knew that it was a much different position from being a senior or lead engineer, but I wasn’t quite prepared for the number of things that I was going to learn.
Overall it was a great experience, so I thought I’d write down some of my learnings here for posterity. So here we go, in no particular order.
- This is completely different from being an engineer – Its not a progression from the job of a senior or lead engineer. It’s a different career entirely. If you expect it to lead engineer + some HR stuff, you are very wrong.
- You will feel overwhelmed – This is a normal feeling. Its a lot like the first real job you took after college. You know what you should be doing, but actually doing it turns out to be a lot harder.
- Meetings Meetings Meetings – You no longer have a maker schedule. As a manager, your schedule is now interrupt driven. This is good. People are interrupting you instead of your team. Helping remove distractions so they can stay in flow state is an important part of your job.
- Managing up is just as important as managing down – Part of your job as a manager is to set and manage expectations within the rest of your organization for the work your team is doing. Knowing what information is worth sharing up the chain is just as important as knowing what information to keep back.
- Relationships matter – As an individual contributor your relations within your team matter a lot. Outside? Not quite as much, but still important. As a manager, your relationships outside of your team matter lots. Cultivate them. Have a drink after work with other managers, directors, product people, whatever. Having strong bonds with these people will make it easier to resolve conflicts because your relationship won’t start out as adversarial.
- Choose words wisely – Whether you think they should or not, the words you use now carry more weight. Choose them carefully.
- Toxic people – After managing for awhile you start to identify people can be toxic to a team. This doesn’t mean that they always are, but they possess the ability to be. They may not even realize it. Don’t be afraid to call them out (in private) if they are being a detractor.
- Hands off – Sometimes managing people and a team is knowing when not to manage at all. Some teams are jelled together really well. All you need to do is remove blockers and let ’em rip. Other teams need a little more hand-holding. This is ok. Just know which team is which. If you hand-hold a high performing team you will make them less effective.
- Always be honest – You are managing groups of intelligent highly sought after engineers. Don’t treat them like children. If they have questions, answer them honestly. If you can’t tell them something for some reason, make sure they understand you aren’t trying to be evasive. In general people like candidness.
- 1 on 1 meetings – You should try to have 1:1 meetings with all of your employees, but leave the cadence up to them. Some people want more interaction, others want less. In my experience, the more senior the person the less 1:1 time they want or need.
One last note before I go: Imposter syndrome is real. I’ve always known I was a good engineer. My track record delivering, career, and salary path all back up that idea of myself. As an engineering manager I have no track record, so I feel like an imposter sometimes. You get over it, but it hits hard.