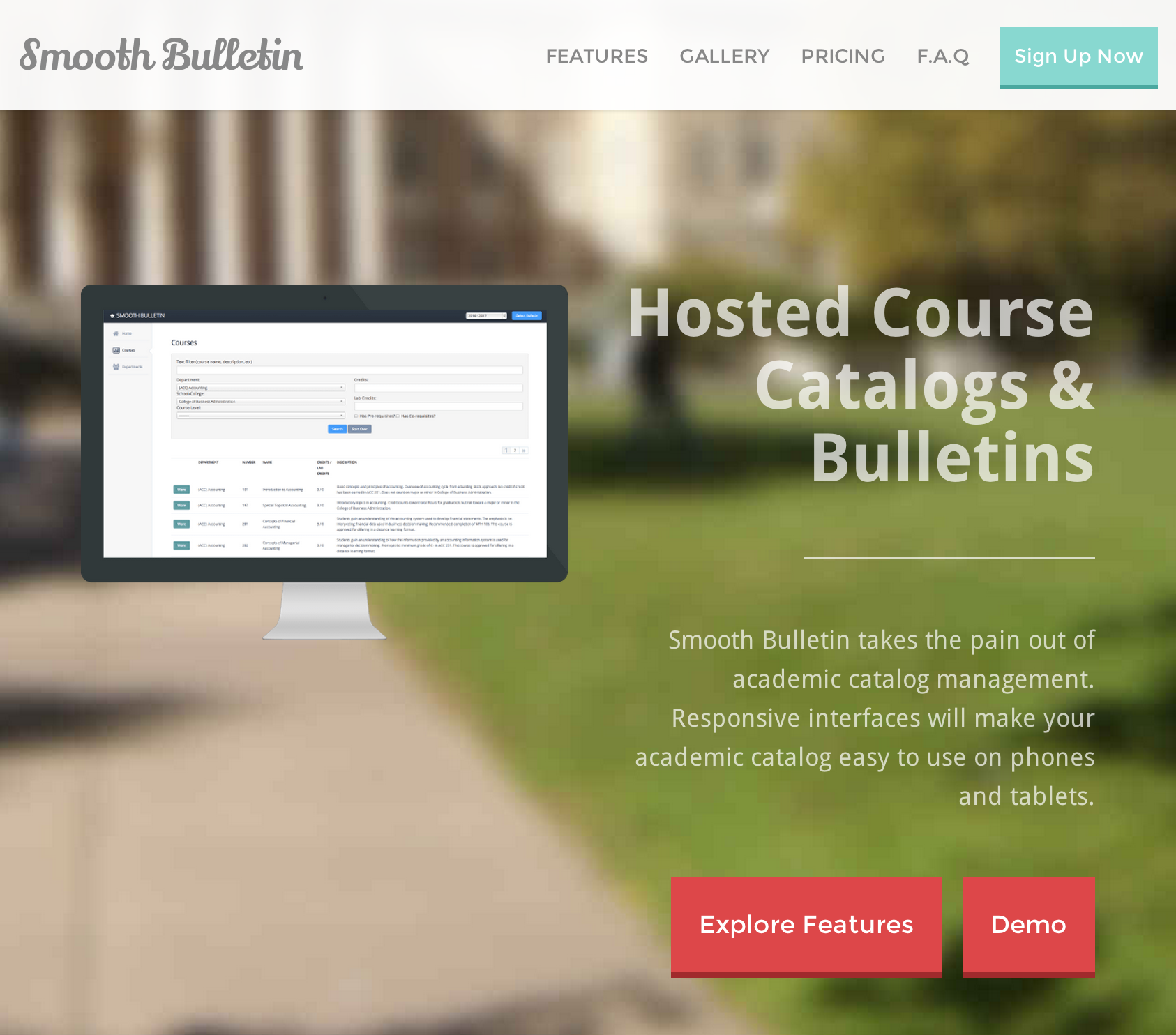
If you want to skip the restoration stuff, the final product can be found at https://re-cycledair.com/starwars/Entrance.html.
A long time ago in an era just before the first dot-com bust, I was a bright-eyed child with aspirations to make the greatest Star Wars web site of all time. With only Microsoft Front Page Express and a limited knowledge of HTML in hand, the 1999 version of me created the best Star Wars web site the world had ever seen.
Unfortunately I was hosting it on my ISPs free web hosting area. When that ISP was later gobbled up by another company, all traces of my website were gone… or so I thought. Recently I discovered that most of it still exists on the Way Back machine, however it’s in poor shape. Many of the assets don’t exist anymore, the linking is broke, and the frames just don’t work right in modern browsers. This is my journey to save this little piece of history while using minimal modern techniques. My goal is to have a legitimate 1999 website when I’m done and have it render nicely on most modern web browsers.
The Internet Archive
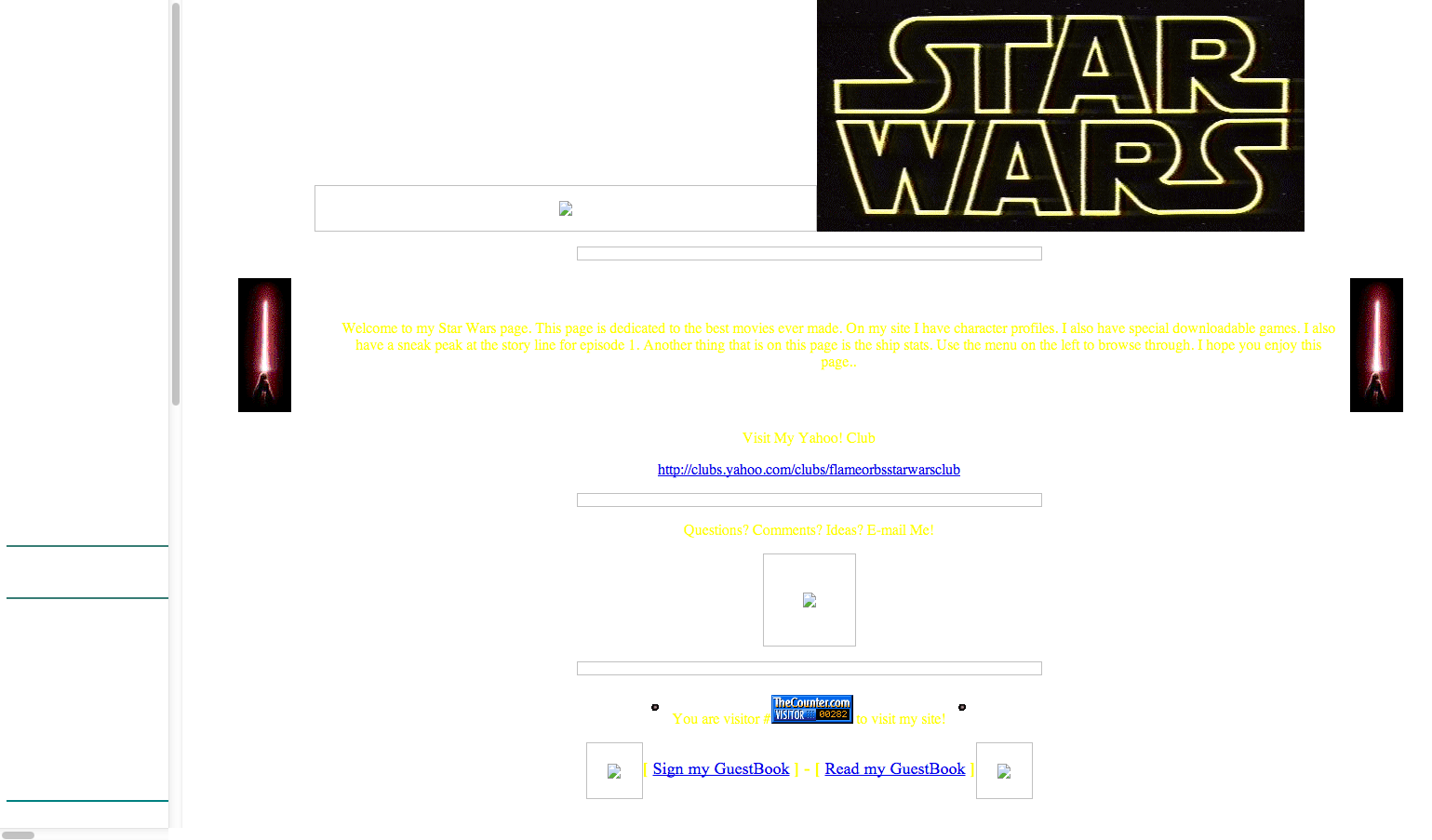
The Wayback machine at the Internet Archive has long been one of my favorite websites. I love getting nostalgic for the web of the past, my childhood, and history in general. It was awhile ago that I realized it still had some of my original Star Wars website. If you want, check out the capture from 2001. It doesn’t work much at all, but it gives you a good idea of what we’re working with here.

In addition to the main page I also had an “Entrance” page, because you know, every cool web site had an entrance page back then. This one is in slightly better shape, meaning the star field background survived intact.
The Game Plan
My goal for this restoration is to make the website display great in modern web browsers with minimal code changes and without using too many modern techniques. At that point in time, CSS wasn’t really a thing that a ton of people used yet, and even if it was it was beyond my understanding, so I’m going to try and avoid it if at all possible. Javascript was available in most browsers by that time, but I didn’t understand it, so I didn’t use it. However, we do have FRAMES(!), which is going to make things super exciting for everyone still reading.
Now that we’ve laid down some ground rules, here is the order of attack:
- Entrance: Fix / replace broken images.
- Entrance: Clean up the HTML (alignment) and remove anything that the Internet Archive crawler added.
- Main site: Fix / replace broken images
- Main site: Remove dead links. Sadly the Internet Archive couldn’t capture everything.
- Main site: Fix any styling issues that remain.
- Main Site: Clean up HTML (alignment) and remove anything that the Internet Archive crawler added.
Lets get started!
Entrance: Replacing Broken Images
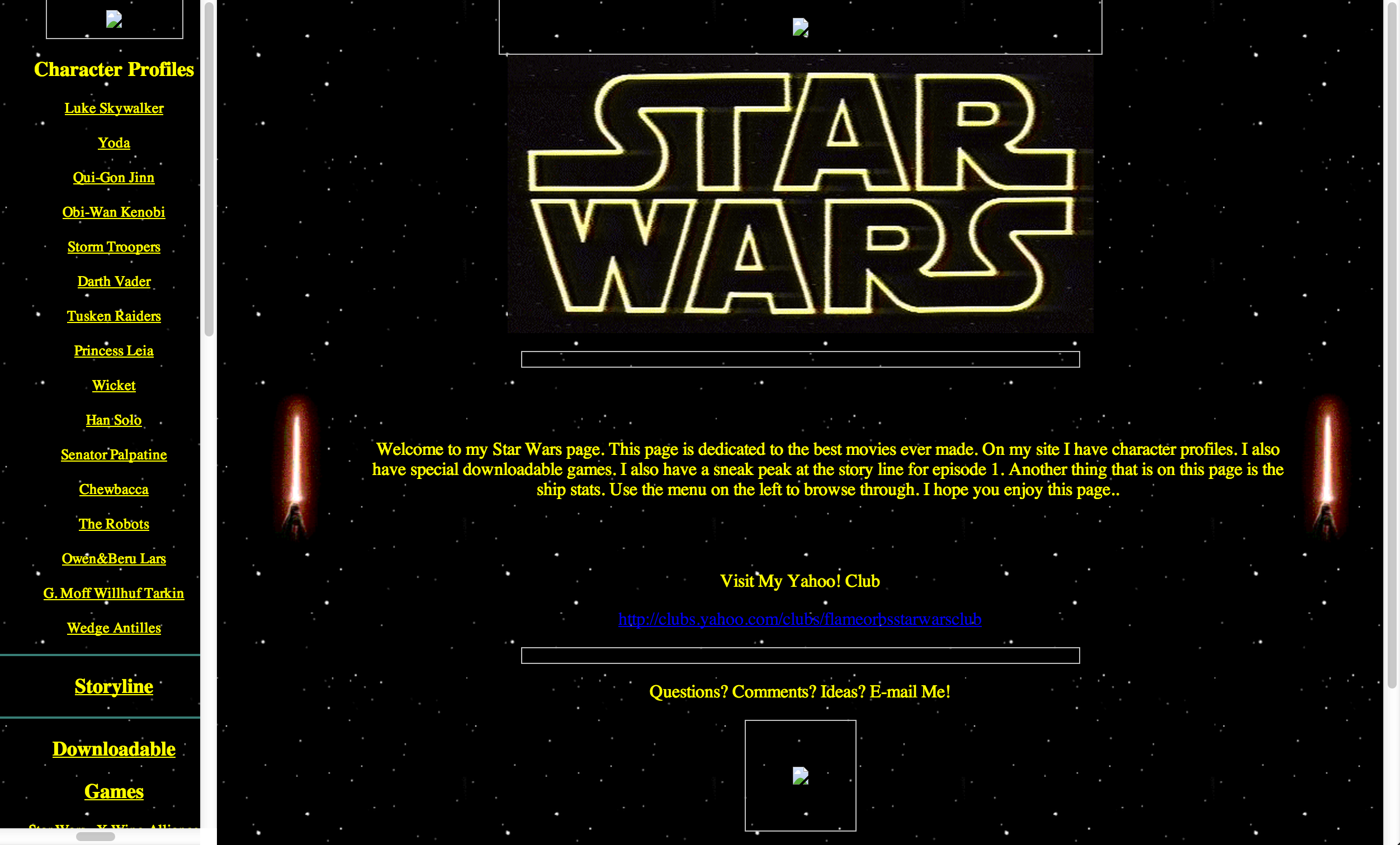
While it’s fantastic that the background star field has survived, the rest of the images didn’t. This is sort of a problem because I have to reach pretty far back into my memory to figure out what was there originally. Luckily, 1999 me wasn’t completely terrible at naming things.
From these file names and memory, I’m going to say that `tie.gif` was a rotating TIE fighter gif, and `starwars.gif` was the Star Wars logo that survived on the main section of the site.
And from this file name we get nothing. Luckily I remember this being an image of Tatooine, roughly 350px x 100px. This site came out a bit before Episode I, so I’m going to assume it was an image from one of the Episode I trailers. At least, thats how I remember it.
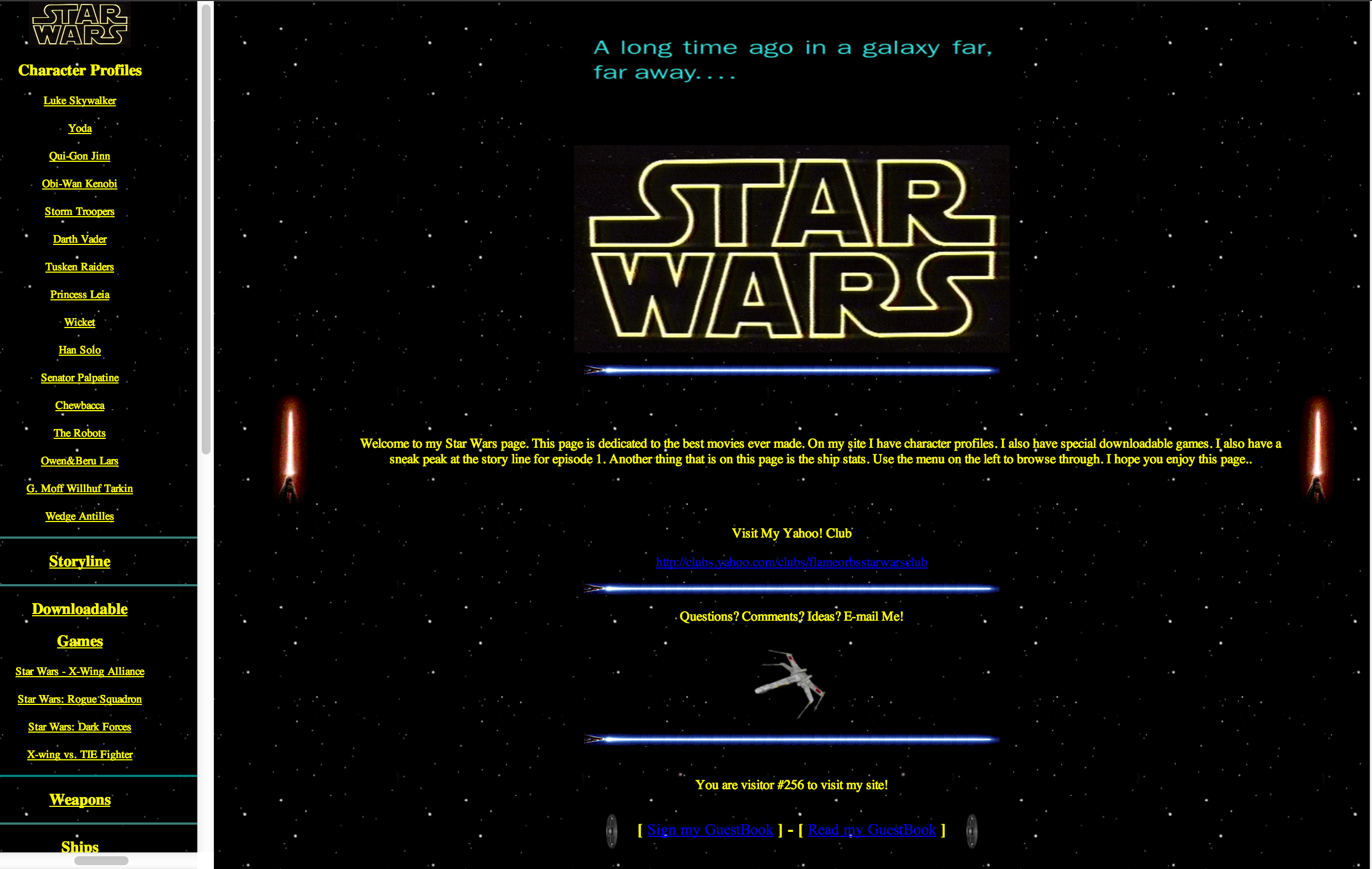
After a bit of digging, I found replacement images for everything but the Tatooine banner. In it’s place, I found a light saber gif that I definitely used on this site somewhere in the past. I also updated the star field to be a little more 1999.
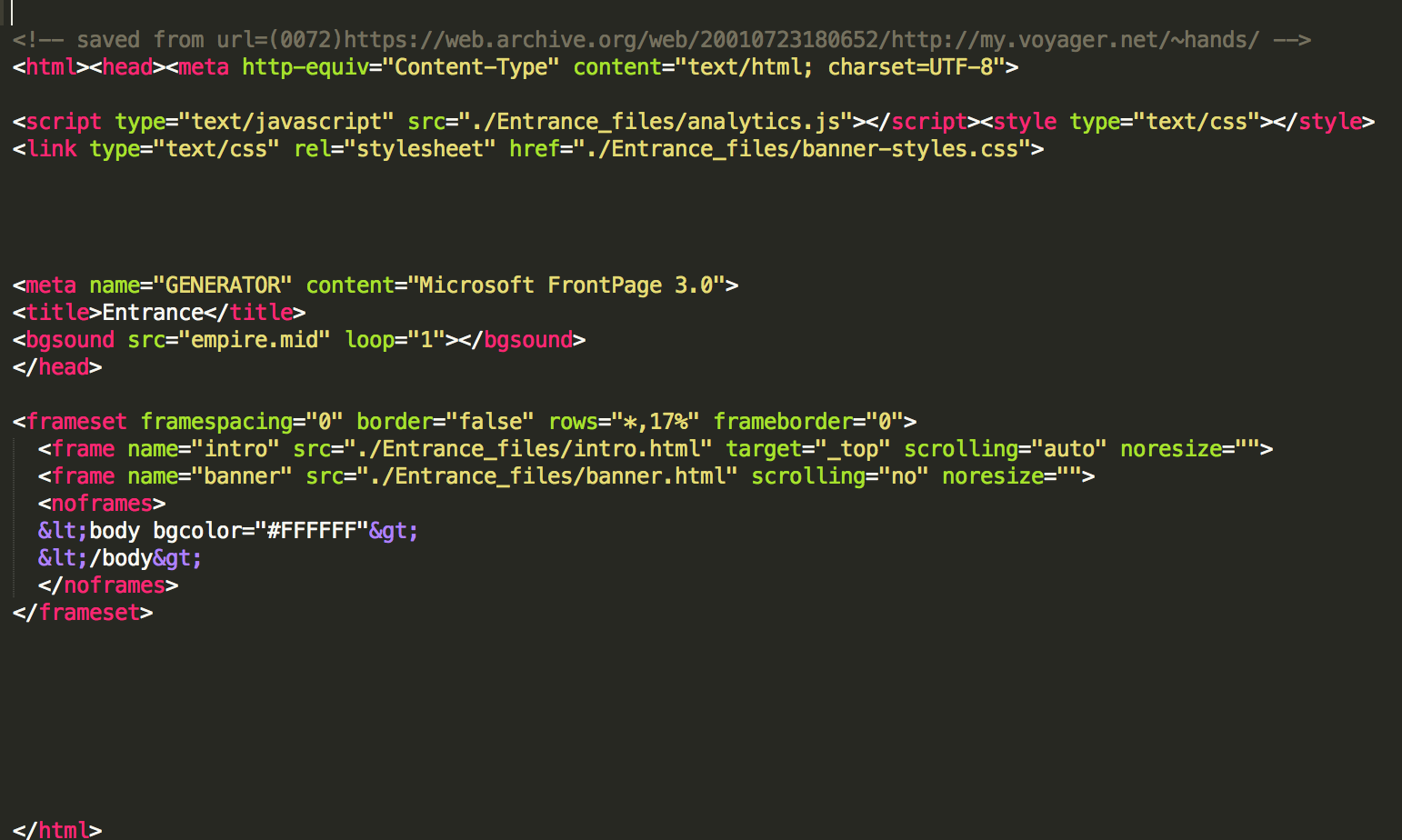
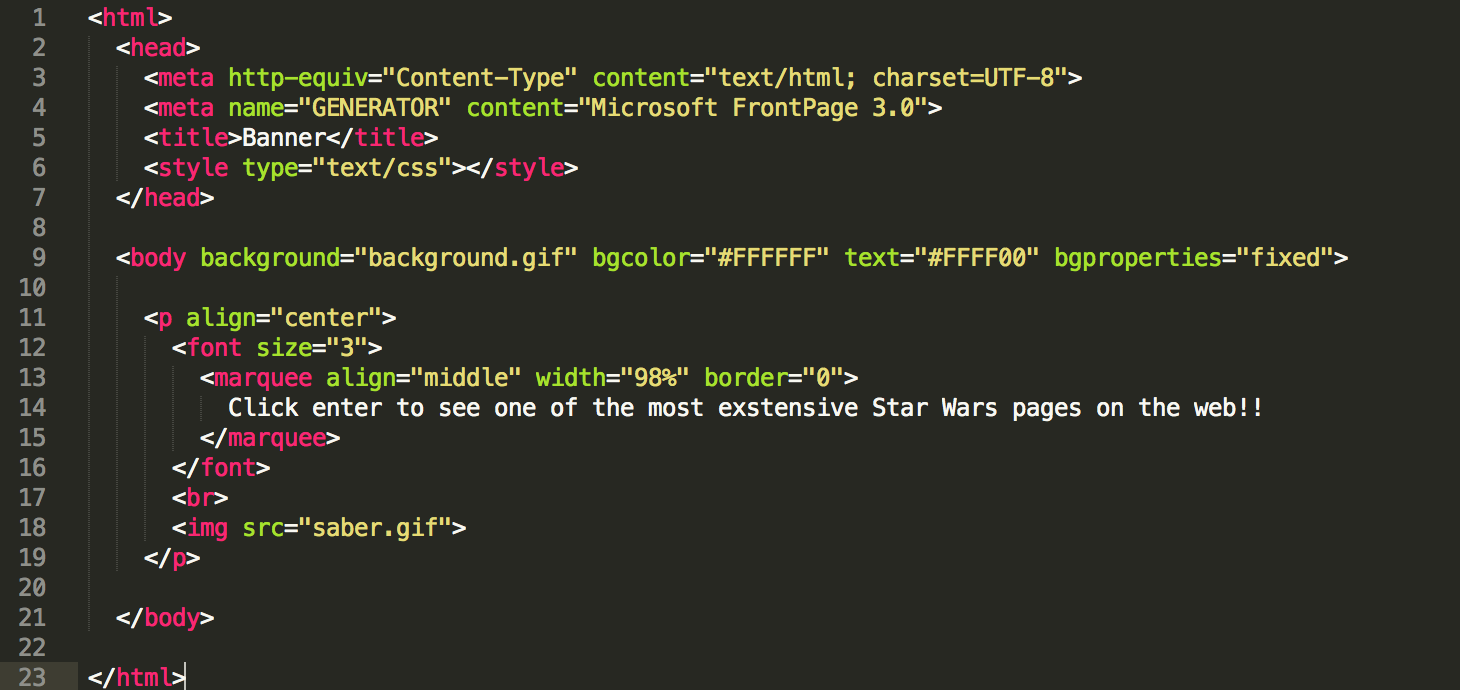
Entrance: HTML Clean Up
Now that the entrance is starting to look like a real 1999 web site again, we can start to clean up the HTML and fix the broken link to enter the site. The entrance area contains 3 pages, 1 to bring the frames together, and 1 for each frame. They currently look like this:
The code isn’t too bad. With a bit of alignment help and some nesting, things are going to look pretty good. Now check out the final product:
Main Site: Fix Broken Images
Now that we have the entrance out of the way, I’ve have a pretty good idea of how this whole restoration will work for the rest of the site. Let’s start by fixing the background on the main site so things are a bit more workable.
Now we’re talking! There are few things that I noticed immediately after getting the background set.
- 1999 me had some pretty sweet design skills
- I should use more animated gifs on my websites
- The frame content on the left isn’t staying inside of it correctly, so I had to scroll to the center to get it to work.
- I had a Yahoo! club!
- I wasn’t so great with words back then. (I was a kid, give me a break)
Looking at the source, there are a few images that aren’t linking quite right.
- Left side: starwars.gif – I think this was just a smaller version of the big logo.
- Left side: deathstar.gif – Definitely a gif of the Death Star. It might have been animated, but I think it was just transparent so that it looked awesome.
- Right side: lettersabove.gif – I honestly don’t know, but it might have been “A long time ago in a galaxy far far away…”
- Right side: pulselightsaber.gif – A pulsing light saber page break. I might just use the static one from the entrance instead.
- Right side: xwing.gif – A rotating X-Wing fighter. Because nothing says “Email me!” like a rotating X-Wing.
After tracking down many of the original images that I used here, the home page now looks like this.
Looking good! Next up, code clean up.
Main Site: Code Clean Up
The code for the main site is in pretty poor condition. There is a ton of code in there from the Internet Archive, it has poor indentation, and in general just isn’t anywhere near the quality of the entrance. Given the amount of code here, I thought using a Github Gist would be better.
Before Code: https://gist.github.com/vital101/56b2783b8e75b00fdac9
After Code: https://gist.github.com/vital101/2d1e6a44ac3ddbb1789d
As you can see I went ahead and re-aligned everything so that it’s more readable, took out all of the javascript and css added by the Internet Archive, and condensed the code a little bit so there wasn’t large bits of whitespace between elements.
The next step in the code cleanup is fixing URLs. If you look at the code, you’ll notice that all the links still point to the Internet Archive. That obviously isn’t going to work for us, so I simply need to replace “https://web.archive.org/web/20010811043323/http://my.voyager.net/~hands/star-wars/” with an empty string, making the link relative.
After fixing links, I found that many of the sub-pages have been lost to time, but there are still a few for us to look at including:
- Luke Skywalker
- Darth Vader
- Princess Leia
- Chewbacca
- G.Moff Willguf Tarkin
- Star Wars: Rogue Squadron
- Weapons
- B-Wing
- Snowspeeder
- Corellian Corvette
- Mon Calamari Cruiser
- At-AT
- Death Star
- Chat
- Movie
Fixing up these pages follows a similar pattern to the entrance page and the main site, so I’ll spare you the details. There were a few interesting things that popped up while I was doing the sub-page restoration though.
- Plagiarism – 1999 me definitely ripped off somebody else with most of the encyclopedic data on characters, weapons, and ships. The change in voice is a dead giveaway.
- Front Page Versions – It appears that I made the entrance and the menu/main page of the main site in FrontPage 3.0, but all of the sub-pages in FrontPage 2.0 (express). FrontPage Express was shareware that came bundled with IE 4 so I know how I got that. I believe I had access to FrontPage 3.0 at my school at that time, which I probably used to generate the frames.
- Xoom – I had completely forgotten about it, but Xoom used to be a free unlimited web host back in the early dot-com days. I used it to host videos, games, and other things. Unfortunately my Xoom site wasn’t crawled by the Internet Archive.
- Java Chat – Back in 1999, there weren’t a whole lot of options for getting a chat room going on your website. Using a Java applet was basically it, so thats what I did. It looks like Xoom offered it’s members a free chat tool, so how could I resist?
- Game Demo – Ah, the good old days. The one game page that survived has some pretty hefty system requirements: Windows 95/98, 32 MB of RAM, Pentium 166. Direct3D card, DirectX 6. Oh, and I also made sure to let people know the estimated download time on 28.8 kbps dial-up modem.
Final Thoughts
The final product can be found at https://re-cycledair.com/starwars/Entrance.html.
While going through this restoration I realized that this is when I knew what I wanted to do with my life. My parents had no idea what I was doing, but they realized that it stimulated my mind so they let me continue to do it anyways. Without that kind of encouragement and freedom to create, I probably wouldn’t be where I am today. This restoration has also re-kindled my respect for the old web. It was simple, but I’m extremely happy that the web has progressed to where it is today.